IBM-量子コンピュータを使った教師あり学習
2018年4月末日 IBM の研究グループから、量子コンピュータを使った教師あり学習の実験結果が発表された。(Supervised learning with quantum enhanced feature spaces) この記事ではこの結果について解説する。
以前 量子コンピュータ×機械学習 の記事で紹介した、Rigetti Computing社による教師無し機械学習と対照的な実験だ。一般的な量子コンピュータと機械学習の関連については、 上の記事で解説したので、今回は Supervised learning with quantum enhanced feature spaces の内容にフォーカスする。
NISQデバイス
近い将来に作られる量子コンピュータは、qubit数は数十から数百に達するが、それぞれのqubitに対する雑音は、十分に取り除くことができないとみられている。そのような量子コンピュータは、研究者の間で NISQ デバイス (Noisy Intermediate Scale Quantum device) と呼ばれる。
量子コンピュータ研究者たちは、これらのNISQデバイスをなんとか応用しようと躍起だ。そのような中で、現在有力なのは、古典コンピュータとNISQデバイスを組み合わせて使う、 「古典-量子ハイブリッドアルゴリズム」 である。これは、ある問題が与えられたとき、それを古典コンピュータとNISQデバイス、それぞれの得意分野に2分割することで、雑音だらけの量子コンピュータでも有効活用できることを示そうという枠組みだ。
今回紹介する実験結果も例に漏れず、この枠組みにのっとったものである。
教師あり学習のアルゴリズム
そんなハイブリッドアルゴリズムの枠組みで、教師あり学習を行うには以下の図のようにする。通常の機械学習で使われるニューラルネットワークと対比させながら考えるとわかりやすいと思うので、図では並べてニューラルネットも示した。
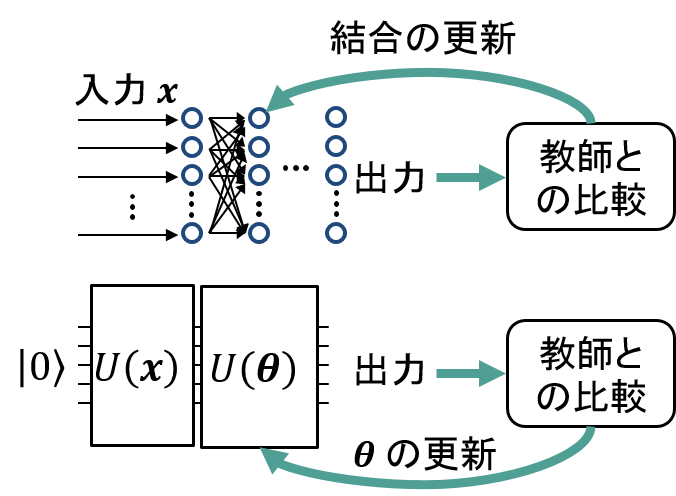
(上) 通常のニューラルネットによる教師あり学習。(下) NISQデバイスによる教師あり学習の概念図。ニューラルネットの入力部分は$U(\boldsymbol{x})$という量子ゲートが担い、ネットワーク部分を $U(\boldsymbol{\theta})$ という量子ゲートが担う。
この方式では、入力のやり方 $U(\boldsymbol{x})$ と量子ビットのつなぎ方 $U(\boldsymbol{\theta})$ の具体的な形が学習の能力を決める。IBMの実験で使われた$U(\boldsymbol{x})$ と $U(\boldsymbol{\theta})$ を少し詳細に解説しよう。ここからはかなり技術的な話になる。
実験
実験では、IBM の 5 qubit デバイスが使われている。二次元の実数値データ $\boldsymbol{x}=(x_1,x_2)$ を入力データとし、これらを2つのラベルに分類するタスクが行われた。
入力 $U(\boldsymbol{x})$
データ$\boldsymbol{x}=(x_1,x_2)$の入力には 1, 2 番目の qubit に作用する、次の量子ゲートが使われている。
$$ U(\boldsymbol{x}) = \left(e^{i(x_1Z_1 + x_2Z_2 + x_1x_2Z_1Z_2)}H^{\otimes 2}\right)^2 $$
ネットワーク $U(\boldsymbol{\theta})$
上の入力ゲートによって作られた状態に、ネットワークに相当する量子ゲート$U(\boldsymbol{\theta})$が掛けられる。これには、(i)番目のqubit に作用する 1 qubit の任意回転のゲート$U_i(\theta_i)$と、(i,j)番目のqubitに対するCZ ゲート $CZ_{ij}$ を組み合わせて、次のようなものが使われている。CZゲートは、直接CZゲートをかけられるqubit間の全ての組み合わせ $E$ で行っている。
$$ U(\boldsymbol{\theta}) = \left(\prod_{i=1}^5 U_i(\theta_i) \prod_{(i,j)\in E} CZ_{ij}\right)^l$$
$l$は0から4まで試したようだ。実験結果をみると$l=2$で十分なように見受けられた。
出力
出力は $Z_1Z_2$ を測定して取り出す。$Z_1Z_2$が$\pm 1$のどちらになるかによって分類を行うのだ。
コスト関数
教師あり学習におけるコスト関数とは、教師データ$m(\boldsymbol{x})$と出力の比較を行う関数である。出力が教師データと近ければ近いほど小さくなるような関数を使う。この実験では、間違えて分類してしまう確率の平均値
$$ C = \frac{1}{|T|} \sum_{\boldsymbol{x}\in T} P(Z_1Z_2\neq m(\boldsymbol{x}))$$
をコスト関数としている。$T$は訓練データの集合を表し、$|T|$は訓練データの数を表す。もちろん、1度の測定によっては確率は求まらないので、何度か測定を繰り返すことになる。
最適化手法
擬似的に勾配最適化を行う SPSA (Simultaneous Perturbation Stochastic Approximation) が使われている。SPSAは、最適化の繰り返しのたびに、ランダムに選んだ1つの方向 $\hat{\boldsymbol{\theta}}$ への差分をとることで、その方向への勾配を近似し、その大きさに応じてパラメータを変化させていく手法である。
実験結果

論文のFig. 3では、このような実験によって、黒点と白点の二次元データが赤い領域と青い領域に分類できていることが示されている。
おわりに
今回のIBMの実験だけでは無く、少し前にはRigettiから機械学習のハイブリッドアルゴリズムの実験結果が発表されている。機械学習に限らず、これからもハイブリッドアルゴリズムはどんどん発展していくだろう。注目だ。
追記:
この論文は2019年3月にNatureに掲載された。